Monolith to Microservices + Event-Driven Architecture

When we start to develop an application, we do it to solve a problem. At first this problem is quite simple, so a monolithic application for our project looks quite good and is quite effective.
When our system begins to grow, we want to increase the scale of operations, accelerate the rate of change and increase the number of teams, this monolithic architecture becomes difficult to maintain and scale. This is why many companies are drawn to breaking it down into a microservices architecture.
It is a worthwhile journey, but not an easy one.
In this article I want to briefly analyze the challenges involved in migrating a monolithic architecture to a microservices ecosystem.
Stage 1. Monolith.
Monolith
A monolith combines the different components of a system on the same platform: the server, the application -with its source code in a single repository-, a single database, shared infrastructure and its own deployment workflow. We can imagine it as a large container that contains all the information of the application and where all the actions that take place in our system will occur.
In this article we will use the following e-commerce scenario:

So far everything works fine, the project has just started, we are few in the team and we can add new functionalities and track everything easily.
💣 It turns out that the idea has potential, the application becomes known, the company invests in marketing, thousands of users register in the application, traffic increases (🔥) and when we realize…

- We have 10,000 times more POST requests and we are not prepared for it.
- Our databases are affected and no longer respond as smoothly as they used to.
- GETs on the users endpoint will take longer to respond (if they still respond).
💡 Due to a peak load in one of our endpoints such as Products, we are affecting the other components that we have in our application, such as Users. If we want to get ahead and be resilient to these variations in load we should manage the architecture more efficiently.
Advantages of monolithic architecture:
✅ Ideal for managing small applications with little complexity.
✅ Simple workflow to implement and test new use cases.
✅ Easy to add new features and find bugs.
Disadvantages of monolithic architecture:
❌ Every time we want to upload new code to production, we must deploy the entire application again.
❌ If a module of a monolithic architecture fails, the entire application will stop working.
❌ Difficult to scale the development team, since everyone will be modifying the same code at the same time, which generates conflicts and slows the productivity of the team.
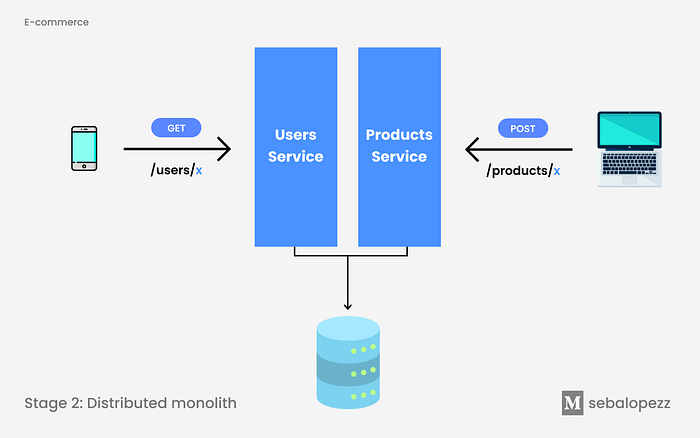
Stage 2. Shared-infra monolith
To cover the disadvantages of the previous model, a new alternative arises: separating the monolith into two services a.k.a Distributed monolith 🤟🏼. Each application (users and products) has its dedicated server with its endpoints, and its own deployment processes, thus allowing to deploy an application without the need to deploy other services. At the code level it could be described as two repositories, one for each service, or a single repository with two sub-modules.
Advantages with the distributed monolith model:
✅ We gain scalability in each application. Each application now has the ability to be in its own language. Separate development and deployment flows.
✅ We gain scalability of the development teams: we can divide and specialize the development teams as well as separate each application with its CVS code repository.
💣 Everything sounds good up to here, but if we raise the scenario with load peaks again in one of our endpoints, for example products, this affects our database, which is SHARED 😭, and if we share infrastructure we go back to the same problem as before…
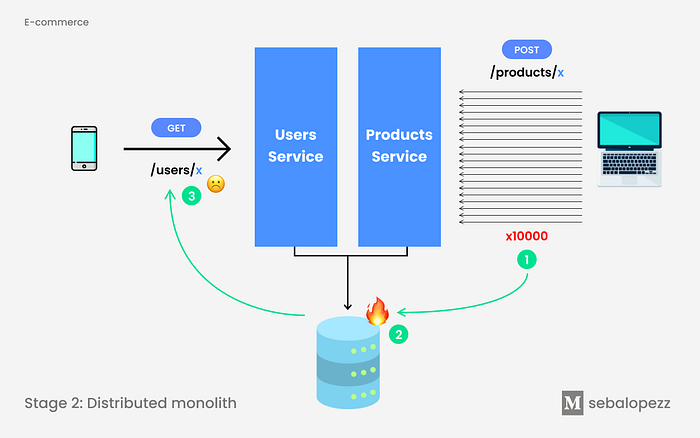
Disadvantages with the distributed monolith model:
❌ We cannot scale the infrastructure. Bottlenecks are generated in the database.
❌ Compatibility in the database schemas: when making modifications, each team must be aware of the alterations and how to treat them from their services.
Stage 3. Microservices architecture.
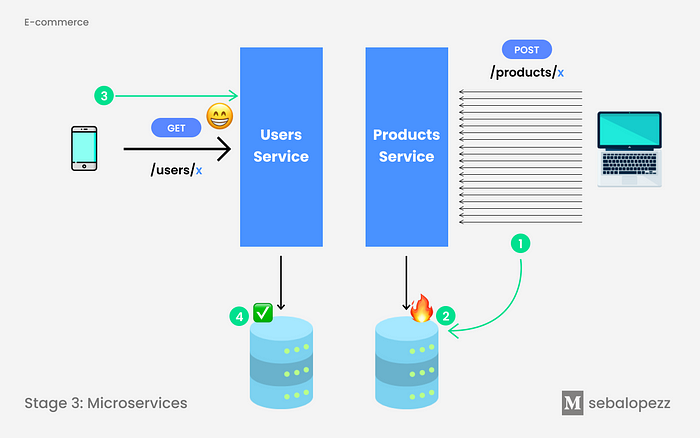
We no longer share the databases. We were able to divide the monolith into multiple parts, known as [micro]services that communicate with each other to have the same result as the monolith. We can imagine them as smaller containers but that are coupled together 🧐 and that causes it to become the same as the monolith but in a more organized way.
So far everything looks good, the Products database crash would not affect the Users microservice 🎉.
💣 But if we remember the first image where we presented the scenario, to respond to the GET request of users, we need information from the products microservice. These microservices communicate with each other to have the same result as the monolith and generate what is known as “The Domino effect”.
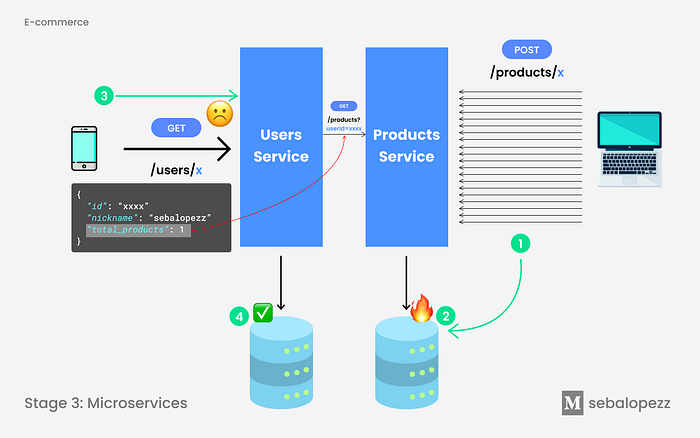
The Domino Effect
The domino effect is a microservices anti-pattern in which services are not sufficiently decoupled to prevent outages in one service from effecting others. When services are tightly coupled to one another, failures in upstream services can cause downstream services to fail in turn. This can create a catastrophic chain reaction of cascading failures.
If Products [micro]service fails or is unavailable for any reason, it will create a domino effect which will cause User [micro]service to fail in turn.

Common advice for this situation is to introduce a circuit-breaker between services, however this does not solve the problem entirely, it only allows a service to fail faster and in a more controlled manner.
To mitigate the domino effect we should strive to make services more autonomous by minimizing their dependence on other services. When a service needs to communicate with other services or resources, that communication should be asynchronous. Consider for example using Event-Driven Architecture.
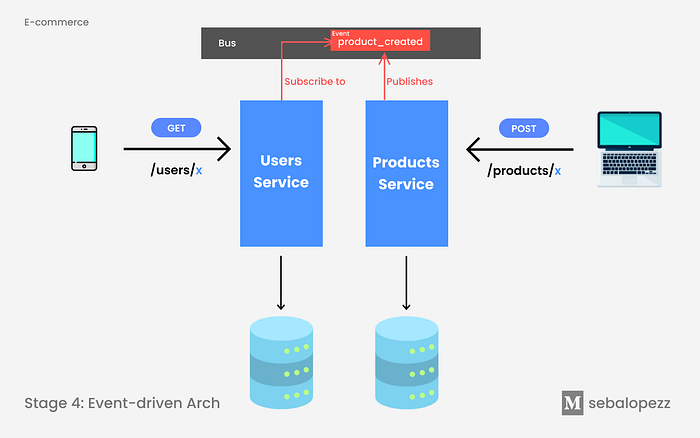
Stage 4. Event-Driven Architecture.
An event-driven architecture uses events to trigger and communicate between decoupled services and is common in modern applications built with microservices. An event is a change in state, or an update, like an item being placed in a shopping cart on an e-commerce website. Events can either carry the state (the item purchased, its price, and a delivery address) or events can be identifiers (a notification that an order was shipped). (AWS)
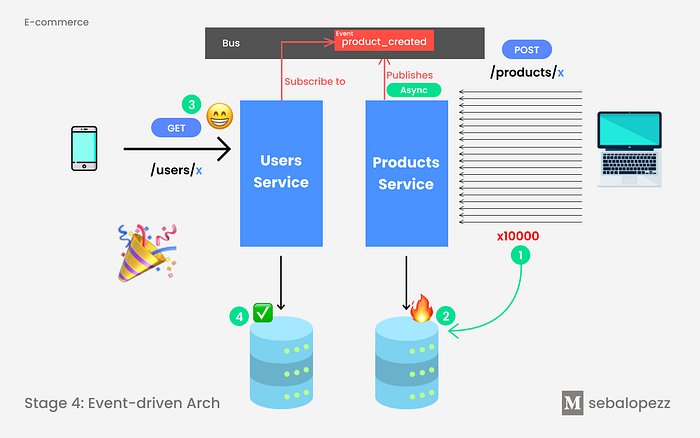
With this approach, when a new product is created, the Products [micro]service publishes the product_created event on an event bus. The Users [micro]service subscribes to this event bus. Every time it hears an event from product_created it will look for that user and make a +1 in the total of products it has.
Before, the computational cost of calculating the total number of products was made at the time of reading this data. With this new approach, we move this responsibility of calculating the total at the moment in which the modification occurs on the state that we are modifying, that is, on the fact of publishing a new product. Every time we create a new product, we react (💡) to this change and increase the counter that we have in the user service. The data modeling will be optimal, because the only information I need about products -in this case- is the total number of products that a user has published.
Why do we call Microservices independent when they still rely on other services?
Of course, services are dependent on others to form a larger application that contains them, but services are considered independent in the sense that they can scale and be modified without interacting with other services. With this model we achieve that the services are able to stand on their own when a dependency service is not available and we avoid the domino effect.
Advantages of an event-based architecture:
✅ Less communication (blocking latency)
✅ Decoupling
✅ More reactiveness
✅ We can scale the implementation, following the SOLID Open/Close principle since now we can add n more services that consume this service, without the need to modify this service.
New set of problems:
❌ Eventual consistency
❌ Handle duplicated events
❌ Handle disordered events
❌ Implications at the testing level. Testing all the actions derived from the main action can no longer be done in a single test of a single service.
Conclusion
Monolithic architectures are attractive because they allow us to deliver new functionalities quickly in a short time, but as we add more and more functionalities it becomes hell to maintain a tremendous system without something being affected by any changes we have made. Although microservices are not the solution that solves all our problems, they have more advantages than continuing to maintain a monolithic architecture.
It is important to know that there is a high overall cost associated with decomposing an existing system to microservices and it may take many iterations. It is necessary to closely evaluate whether the decomposition of an existing monolith is the right path, and whether the microservices itself is the right destination.
Of course, we could have multiplied the number of MySQL slaves or created multiple instances of microservices from the beginning to balance the load, but the objective of this article is to find an alternative solution to make efficient use of resources.
